

La construction d'une visualisation de données, ce n'est pas que de la visualisation !
Aujourd’hui on regarde en détail les grandes étapes de création d’une data-viz (ou visualisation de données). Ces explications s’adressent autant à un utilisateur – producteur d’une visualisation – qu’à un profane qui découvre le monde de la visualisation de données et qui voudrait en savoir plus sur les aspects pratiques et techniques. Nous explorons donc en détail les étapes cruciales pour construire des visualisations percutantes à l’aide d’outils tels que Power BI ou Tableau, avec quelques conseils pratiques généraux pour chacune des étapes. Nous n’aborderons en revanche que très partiellement la question du stockage des données, qui fera l’objet d’un autre article spécifiquement dédié sur le sujet.
La création de visualisations de données nécessite un processus bien défini, de la préparation minutieuse des données à la modélisation astucieuse pour gérer les consommations de ressources si les données sont conséquentes.
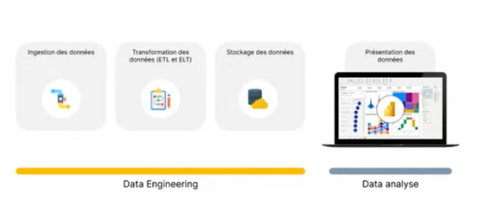
Source : https://learn.microsoft.com
1) Le socle : s’assurer de la bonne qualité et préparer les données
Avant même de penser à la visualisation, la qualité des données est primordiale. C’est un point crucial sur lequel vous devez accorder une grande attention : pas de visualisation de données sans des données de bonne qualité.
La précision et la fiabilité des données sont donc essentielles pour obtenir des résultats significatifs et exploitables. Vous devez donc évaluer à la fois la complétude, la disponibilité, l’intelligibilité, l’intégration, la conformité, l’intégrité ou encore la sécurité de celles-ci.
Assurez-vous de nettoyer, formater et enrichir vos données pour garantir leur fiabilité. Utilisez des outils de préparation comme Power Query dans Power BI ou Tableau Prep pour simplifier ce processus. Il faut veiller à traiter les données manquantes, supprimer les doublons et normaliser les unités.
💡 Quelques bonnes pratiques :
- Établissez des procédures de qualité des données dès le départ, en incluant des règles pour la validation, la cohérence et la conformité aux formats requis.
- Utilisez des outils de préparation automatisés pour gagner du temps et minimiser les erreurs, souvent humaines, et optimiser le temps de préparation des données.
2) Les mains dans le cambouis : la modélisation des données
La modélisation des données est le fondement d’une visualisation réussie. En créant des relations logiques entre les tables, avec des mesures clés et l’utilisation de calculs DAX ou de formules SQL par exemple selon le langage de vos outils pour obtenir des indicateurs pertinents. Les plateformes existantes proposent aujourd’hui une interface plutôt conviviale pour cette étape, facilitant la création de modèles de données complexes.
💡 Quelques bonnes pratiques :
- Hiérarchisez vos données pour faciliter la navigation.
- Définissez des relations logiques entre les tables et en structurant les hiérarchies de manière intuitive.
- Utilisez des noms de champs explicites pour une compréhension claire et pour la lisibilité du modèle, facilitant ainsi la compréhension de la structure des données.
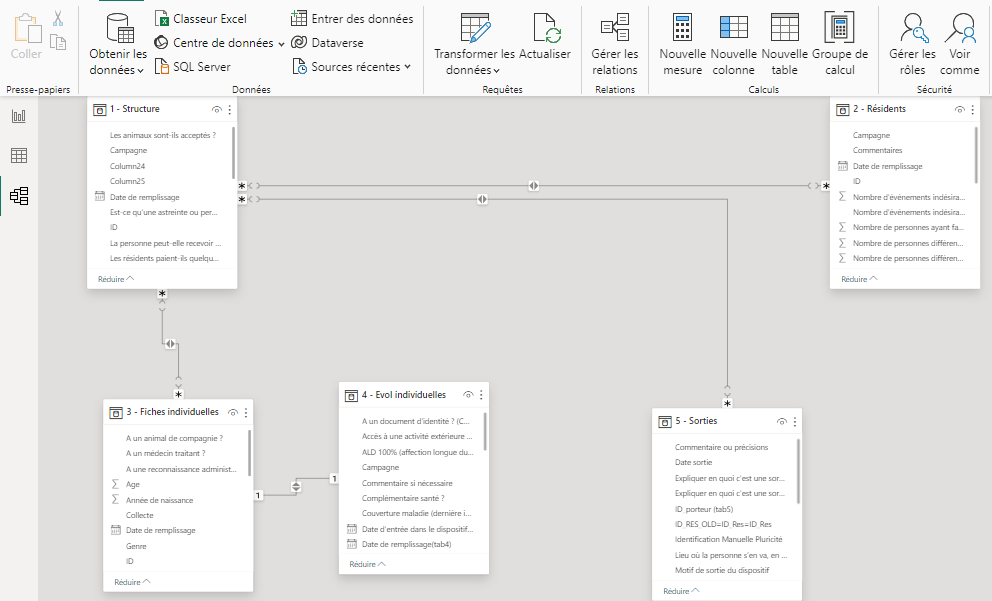
Exemple de modèle de données, avec lien inter-tables (vue sur Power BI)
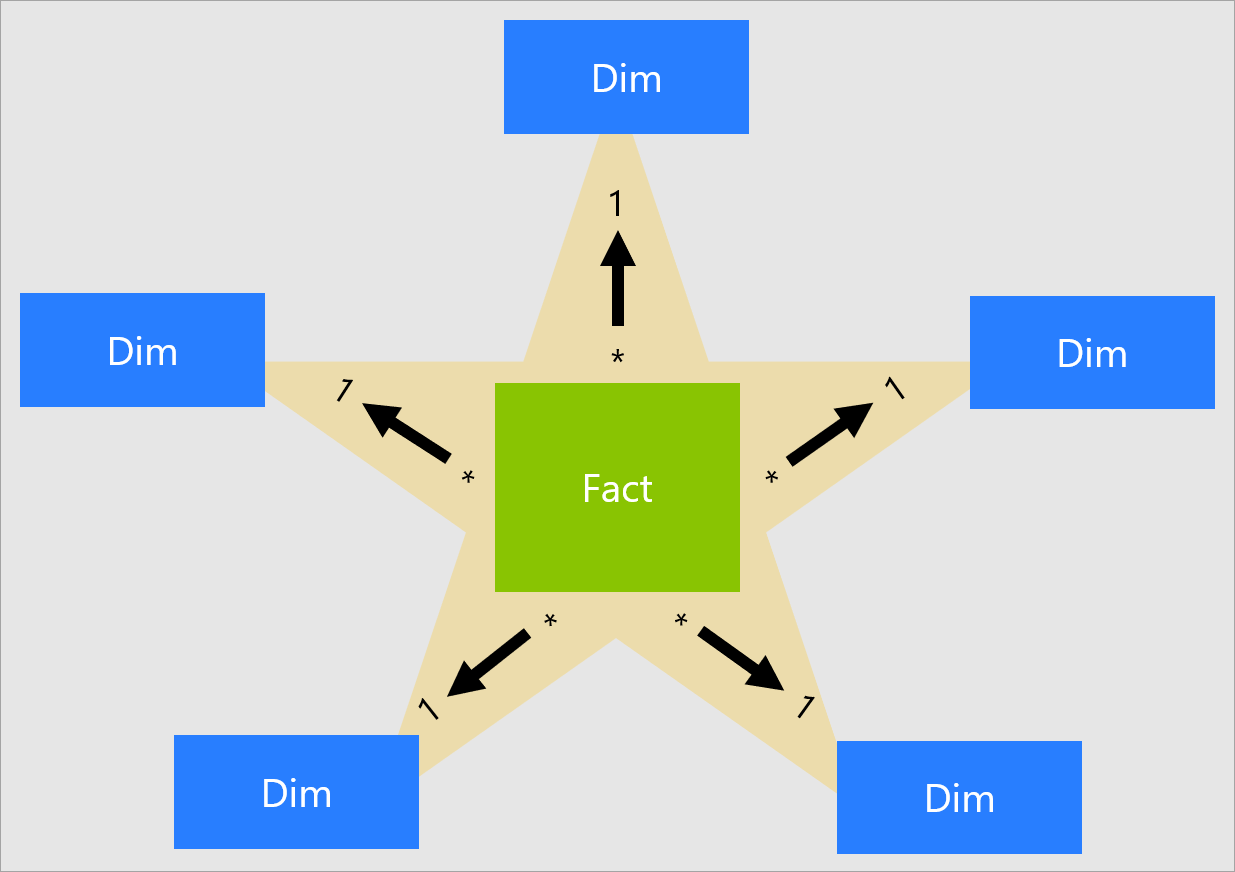
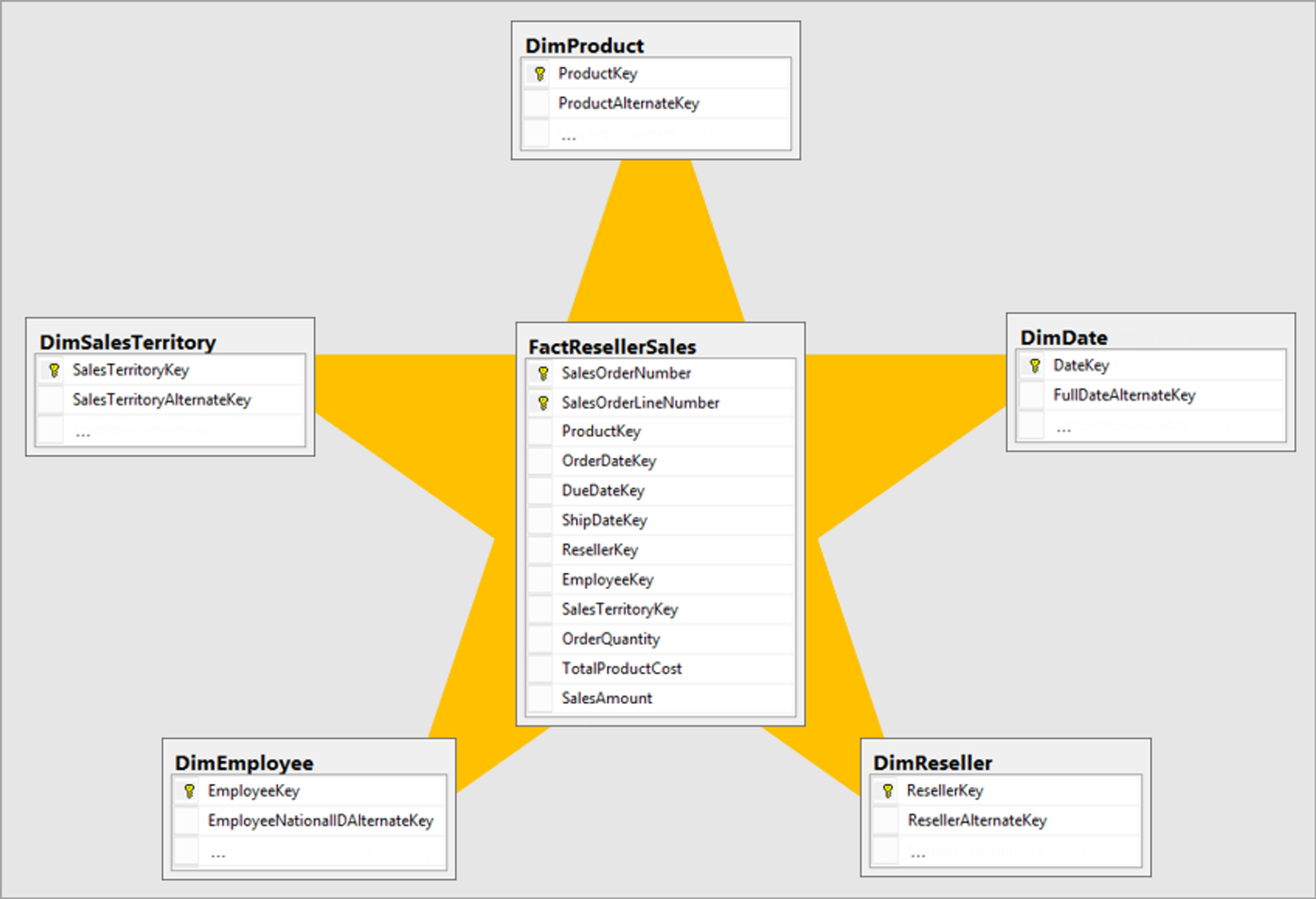
Un modèle de plus en plus utilisé : vue d’ensemble du schéma en étoile
Le schéma en étoile est une approche de modélisation mature largement adoptée par les entrepôts de données relationnels. Les modélisateurs doivent classer leurs tables de modèle en tant que table de dimension ou table de faits.
Les tables de dimension décrivent les entités : les choses que vous modélisez. Les entités peuvent inclure des produits, des personnes, des lieux et des concepts, y compris le temps lui-même. La table la plus cohérente que vous trouverez dans un schéma en étoile est une table de dimension de date. Une table de dimension contient une ou plusieurs colonnes clés qui jouent le rôle d’identificateur unique et de colonnes descriptives.
Les tables de faits stockent des observations ou des événements et peuvent être des commandes client, des soldes de stock, des taux de change, des températures, etc. Une table de faits contient des colonnes clés de dimension qui se rapportent aux tables de dimension et des colonnes de mesures numériques. Les colonnes clés de dimension déterminent la dimensionnalité d’une table de faits, tandis que les valeurs clés de dimension déterminent sa granularité. Par exemple, imaginez une table de faits conçue pour stocker des cibles de ventes qui a deux colonnes clés de dimension : Date et ProductKey. Il est facile de comprendre que la table a deux dimensions. Toutefois, vous ne pouvez pas déterminer la granularité sans tenir compte des valeurs clés de dimension. Dans cet exemple, supposez que les valeurs stockées dans la colonne Date sont le premier jour de chaque mois. Dans ce cas, la granularité se situe au niveau produit/mois.
En règle générale, les tables de dimension contiennent un nombre relativement petit de lignes. En revanche, les tables de faits peuvent contenir un très grand nombre de lignes et croître au fil du temps.
Un modèle bien conçu fournit des tables pour le filtrage et le regroupement et des tables pour la totalisation. Cette conception répond bien aux principes des schémas en étoile :
- Les tables de dimension prennent en charge le filtrage et le regroupement.
- Les tables de faits prennent en charge la totalisation.
A noter qu’il existe d’autres schémas de modélisation de données : le schéma en flocon de neige, où les tables de dimension sont décomposées en sous-dimensions, et il est plus normalisé que le schéma en étoile.
Point connexe mais important ! Définir la cardinalité des relations
Cardinalité
La cardinalité permet de comparer le nombre de lignes au nombre de colonnes dans la feuille. En particulier en ce qui concerne les bases de données, la cardinalité est généralement une mesure du nombre de valeurs distinctes que vous avez dans une colonne par rapport au nombre de lignes.. Dans Power BI par exemple, l’option Cardinalité peut avoir une des valeurs suivantes :
Plusieurs à un (*:1) : Une relation plusieurs-à-un est le type de relation par défaut le plus courant. Elle signifie que la colonne d’une table donnée peut avoir plusieurs instances d’une valeur, tandis que la table liée, souvent appelée table de recherche, n’a qu’une seule instance d’une valeur.
Un à un (1:1) : Dans une relation un-à-un, la colonne d’une table n’a qu’une seule instance d’une valeur particulière et la table liée n’a qu’une seule instance d’une valeur donnée.
Un à plusieurs (1:*) : Dans une relation un-à-plusieurs, la colonne d’une table n’a qu’une seule instance d’une valeur particulière, tandis que la table liée peut avoir plusieurs instances d’une valeur.
Plusieurs à plusieurs (:) : Avec les modèles composites, vous pouvez établir des relations plusieurs-à-plusieurs entre des tables, ce qui élimine la nécessité d’avoir des valeurs uniques dans les tables. Les solutions de contournement précédentes, comme la présentation de nouvelles tables uniquement pour établir des relations, sont également supprimées. Pour plus d’informations, consultez Relations avec une cardinalité plusieurs-à-plusieurs.
Pour plus d’informations sur le changement de cardinalité, consultez Présentation des options supplémentaires.
3) Le bouquet final : la construction de la visualisation
La phase finale est l’étape qui est souvent perçue comme la plus excitante avec la construction de la visualisation à partir de types de graphiques appropriés en fonction de vos données et de vos objectifs. Les solutions existantes sur le marché offrent une variété de visualisations, des graphiques classiques aux cartes géographiques interactives. En personnalisant les couleurs, les axes et les filtres, vous pouvez rendre votre visualisation plus attrayante et informative.
💡 Quelques bonnes pratiques :
- Choisissez des visualisations adaptées à votre message et personnalisez les à votre public, en choisissant des types de graphiques et des représentations visuelles qui résonnent le mieux avec les utilisateurs finaux.
- Utilisez des palettes de couleurs cohérentes pour garantir une expérience visuelle harmonieuse à travers l’ensemble de vos visualisations, renforçant ainsi la compréhension et la mémorisation des informations.
En conclusion
Avec ces grandes étapes présentées ci-dessus, vous avez fait le premier pas pour découvrir et maîtriser le processus de construction de visualisations de données avec des outils tels que Power BI ou Tableau.
Néanmoins l’article ne se veut pas exhaustif, et la consultation de ressources complémentaires sous d’autres formats (format vidéo par exemple) peuvent vous aider à vous former et en apprendre davantage sur les éléments clés à maîtriser pour construire une visualisation de données pertinentes et performantes.
C’est pour cette raison que depuis 2023 Visionary Conseil se forme en continue sur ces outils – avec notamment l’obtention de la certification PL-300 – Power BI Data Analyst – pour répondre à des problématiques de plus en plus pointues d’ingestion, d’extraction, de préparation, de modélisation et de visualisation de données.
Autres ressources / en savoir plus
https://learn.microsoft.com/fr-fr/power-bi/guidance/star-schema
https://www.databricks.com/fr/glossary/snowflake-schema
https://mailchimp.com/fr/resources/cardinality-meaning/
Meetup Power BI sur la modélisation (modèle Kimball) : https://www.youtube.com/watch?v=IRVMebW1RrE
Des inspirations suite à la lecture de cet article ? Ou envie de découvrir d’autres sujets en lien avec la visualisation de données ?
Alors n’hésitez pas à explorer nos différents articles de blogs, à laisser un commentaire ou à partager !

